# 磁盘管理
认识磁盘分区、格式化以及磁盘管理命令的内容。
# 硬盘
计算机使用的主要外部存储器就是磁盘,相对于内存而言,它的读写速度很慢,但是它所存储的信息不受断电的影响。
磁盘又分为软盘和硬盘,软盘是个人电脑最早使用的移动存储介质。其存取速度慢,容量也小,但可装可卸、携带方便。
现在已经普遍不使用软盘了,原因就是我们现在有更好用、更大容量的 U 盘和移动硬盘等作为移动存储介质。所以我们现在常说的磁盘大多时候指的是硬盘。
硬盘(英语:Hard Disk Drive,简称 HDD)是计算机上使用坚硬的旋转盘片为基础的非易失性存储器。
目前常见的硬盘大可分为三类:
- 机械硬盘(HDD)采用磁性碟片来存储;
- 固态硬盘(SSD)采用闪存颗粒来存储;
- 混合硬盘(HHD)是把磁性碟片和闪存集成到一起的一种硬盘。
硬盘的接口主要有 IDE、SATA、SCSI 、SAS 和光纤通道等五种类型。
其中 IDE 和 SATA 接口硬盘多用于家用产品中,也有部分应用于服务器,SATA 是一种新生的硬盘接口类型,已经取代了大部分 IDE 接口应用。
SCSI 、SAS 主要应用于服务器上,普通家用设备一般不支持 SCSI 和 SAS 接口。SAS 也是是一种新生的硬盘接口类型,可以和 SATA 以及部分 SCSI 设备无缝结合。
光纤通道最初设计也不是为了硬盘设计开发的接口,是专门为网络系统设计的,但随着存储系统对速度的需求,才逐渐应用到硬盘系统中,并且其只应用在高端服务器上,其价格比较昂贵。
# 硬盘的物理组成
目前主要使用的还是机械硬盘,其依据台式机与笔记本电脑而有分为 3.5 英寸及 2.5 英寸的大小。
以 3.5 英寸的台式机使用硬盘为例,在硬盘盒里面其实是由许许多多的圆形盘片、机械手臂、 磁头与主轴马达所组成的。

实际的数据都是写在具有磁性物质的盘片上面,而读写主要是通过在机械手臂上的磁头(head)来达成。在运行时,主轴马达让盘片转动,然后机械手臂可伸展让磁头在盘片上头进行读写的动作。
磁头: 磁头固定在可移动的机械臂上,用于读写数据。现代硬盘都是双面可读写,因此磁头数量等于盘片数的 2 倍。磁头数最大值为 255 (8 个二进制位)。
机械手臂: 机械手臂由控制电路控制,可以前后移动,带动磁头,使磁头位于正确的位置。
既然数据都是写入盘片上头,那么盘片上头的数据又是如何写入的呢?
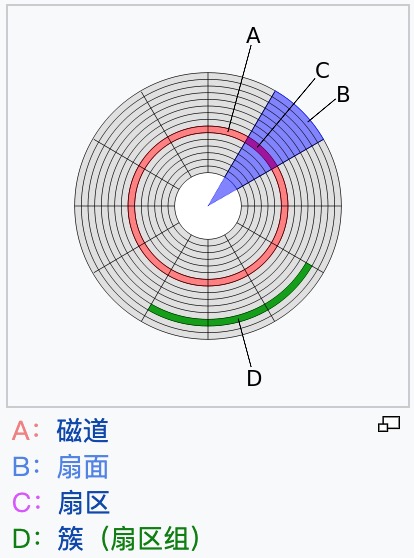
在类似盘片同心圆上面切出一个一个的小区块,这些小区块整合成一个圆形,让机器手臂上的磁头去存取。这个小区块就是磁盘的最小物理储存单位,称之为扇区(sector),而在同一个同心圆的扇区组合成的圆就是所谓的磁道(track)。
磁道: 每个盘面都有 n 个同心圆组成,每个同心圆称之为一个磁道。由外向内分为 0 磁道到 n 磁道。
扇区: 从磁盘中心向外画直线,可以将磁道划分为若干个弧段。每个磁道上一个弧段被称之为一个扇区。扇区是硬盘的最小组成单元,通常是 512 字节。磁道上的扇区数最大为 63 (6 个二进制位)。 簇: 将物理相邻的若干个扇区称为了一个簇。操作系统读写磁盘的基本单位是扇区,而文件系统的基本单位是簇(Cluster)。
由于磁盘里面可能会有多个盘片,因此在所有盘片上面的同一个磁道可以组合成所谓的柱面(cylinder)。
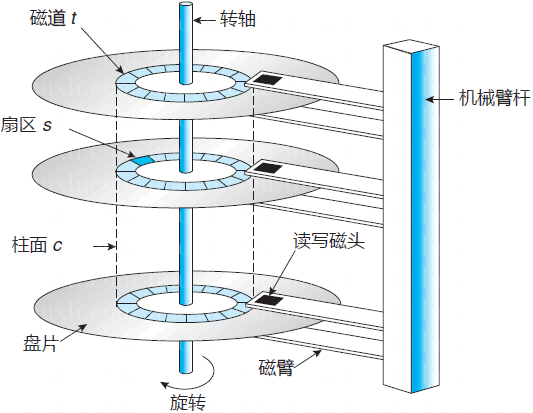
硬盘数据的读写是按柱面进行,即磁头读写数据时首先在同一柱面内从 0 磁头开始进行操作,依次向下在同一柱面的不同盘面(即磁头上)进行操作,只有在同一柱面所有的磁头全部读写完毕后磁头才转移到下一柱面。
由于选取磁头只需通过电子切换即可,而选取柱面则必须通过机械切换。电子切换比从在机械上磁头向邻近磁道移动快得多。因此,数据的读写按柱面进行,而不按盘面进行。读写数据都是按照这种方式进行,尽可能提高了硬盘读写效率。
柱面: n 个盘面的相同磁道 (位置相同) 共同组成一个柱面。柱面数最大为 1023 (10 个二进制位)。
# 磁盘设备在 Linux 下的表示
在 Linux 中一切皆文件,因此它会把设备映射成为一个 /dev 目录下的系统文件,硬盘也是如此。
IDE 接口类型的硬盘设备映射的文件名称前缀为 “hd”,SCSI、SATA、SAS 等接口的硬盘设备映射的文件名称前缀为 “sd”(部分虚拟机或者云主机的名称可能是其他的,比如 “vd”),后面拼接从 “a” 开始一直到 “z” 用来区分不同的硬盘设备,在硬盘名称后面拼接数字形式的分区号用来区分不同的分区。
编号与在主机面板上插槽的位置无关,而是根据 Linux 核心侦测到磁盘的顺序决定的。
比如有六个 SATA 的插槽和两个 SATA 磁盘分。将这两个 SATA 磁盘分别安插在主板上的 SATA1, SATA5 插槽上, 那么这两个磁盘在 Linux 中的设备文件名分别为 /dev/sda 和 /dev/sda。
也就是说,在 Linux 系统中磁盘设备文件的命名规则为: 主设备号 + 次设备号 + 磁盘分区号。
# 文件系统
Linux 文件系统包含排列在磁盘或其他区块存储设备的目录中的文件。
我们熟知的 Windows 系统的概念是在不同的驱动器盘符上(A:,C:,等)使用不同的文件系统,而 Linux 文件系统则截然不同,它是一个以 / 目录作为根目录的树形结构。
事实上,每一个区块设备(如硬盘驱动器分区、CD-ROM 或者软盘)上都有一个文件系统。硬盘布局一定的意义就在于我们通过在称为挂载点的点将文件系统挂载到不同的设备上创建文件系统的单一树形视图。
由此也可见,挂载过程实际上是指挂载某些设备上的文件系统,但人们通常会称之为 “挂载设备”。
新的设备,比如一个硬盘安装到主机之后称为裸设备,若要能够在 Linux 系统中使用必须对其进行如下步骤: 分区 -> 格式化 -> 挂载。
# 分区
对于某些块设备而言,比如软盘、CD 或 DVD 磁盘,通常使用整个媒体作为单个文件系统。但是,对于大型硬盘驱动器,甚至是 USB 存储器,更常见的用法是将可用空间划分为几个不同的分区。
分区是逻辑上的概念,而不是将硬盘真正进行物理上的分割,所以可称为逻辑分区。柱面,通常是文件系统的最小单位,也就是分区的最小单位。
分区的大小可能不同,不同的分区上可以拥有不同的文件系统,因此一个磁盘可以用于多种目的,包括在多个操作系统之间共享该磁盘。
分区信息存储在磁盘的分区表中。分区表列出每个分区的起始柱面和结束柱面的相关信息,关于其类型的信息,以及它是否标记为可引导。
对习惯于使用 Windows 的同学来说,熟知有几个分区就会有几个驱动器,并且每个分区都会获得一个字母标识符,然后就可以选用这个字母来指定在这个分区上的文件和目录,它们的文件结构都是独立的,这非常好理解。
然而对 Linux 用户来说无论有几个分区,都得分给目录使用,它归根结底就只有一个根目录,一个独立且唯一的文件结构。
其中,每个分区都是用来组成整个文件系统的一部分,因为它采用了一种叫“挂载点”的处理方法,它的整个文件系统中包含了一整套的文件和目录,且将一个分区和一个目录联系起来。这时要载入的一个分区就在 Linux 的存储空间的某个目录下获得。
# 分区的目的
创建磁盘分区大概有下面几个目的:
- 提升数据的安全性(一个分区的数据损坏不会影响其他分区的数据)。
- 在不损失数据的情况下重装系统,比如独立设置
/home挂载点,重装系统的时候直接标记回/home,数据不会有任何损失。 - 支持安装多个操作系统。
- 多个小分区对比一个大分区会有性能提升。
- 针对不同挂载点的特性分配合适的文件系统以合理发挥性能。
- 针对不同的挂载点开启不同的挂载选项,如是否需要即时同步,是否开启日志,是否启用压缩。
- 磁盘配额只能对分区做设定。
/home、/var、/usr/local经常单独分区,因为经常会被操作,容易产生碎片。
# 分区的模式
Linux 中主要有 MBR(Master Boot Record)和 GPT(GUID Partition Table)两种分区类型,是在磁盘上存储分区信息的两种不同方式。
分区信息包含了分区从哪里开始的信息,这样操作系统才知道哪个扇区是属于哪个分区的,以及哪个分区是可以启动的。在磁盘上创建分区时,你必须在 MBR 和 GPT 之间做出选择。
# MBR
对于 MBR 而言,开机管理程序纪录区与分区表则通通放在磁盘的第一个扇区,这个扇区通常是 512Bytes 的大小,其中:
- 主要开机记录区(Master Boot Record, MBR): 可以安装开机管理程序的地方,有 446 Bytes。
- 分区表(partition table): 记录整颗硬盘分区的状态,有 64 Bytes。
由于分区表所在区块仅有 64 Bytes 容量,因此最多仅能有四组记录区(也就是通常说的主分区),每组记录区记录了该区段的启始与结束的柱面号码。
在 4 个主分区中,可以有一到三个基本分区(primary partion)和至多一个是扩展分区(extension partion),基本分区不能再分区,而扩展分区不能直接使用,需要再细分为逻辑分区,逻辑分区数量限制视磁盘类型而定。
可见,扩展分区的目的是使用额外的扇区来记录分区信息。
另外,MBR 的主分区号为 1-4,逻辑分区号为从 5 开始累加的数字。需要注意的是,即使只有一个基本分区和一个扩展分区,逻辑分区的区号也只能从 5 开始。
# GPT
GPT 意为 GUID 分区表,驱动器上的每个分区都有一个全局唯一的标识符(globally unique identifier,GUID)。
GPT 克服了 MBR 分区的两个限制:
- 单个分区容量最大为 2 TB。
- 主分区最多只能有 4 个。
支持的最大磁盘可达 18EB,它没有主分区和逻辑分区之分,每个硬盘最多可以有 128 个分区,具有更强的健壮性与更大的兼容性,并且将逐步取代 MBR 分区方式。
GPT 分区的命名和 MBR 类似,只不过没有主分区、扩展分区和逻辑分区之分,分区号直接从 1 开始累加一直到 128。
# FDISK
fdisk 是 Linux 的磁盘分区表操作工具。该命令不可直接使用,当使用 fdisk -l 时,系统将会把整个系统内能够搜寻到的装置的分区均列出来。
通过指定设备名称可以查看指定设备的分区情况。
fdisk -l /dev/sda
Disk /dev/sda: 20 GiB, 21474836480 bytes, 41943040 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 1B317E33-3B86-4906-938B-0CB82C7EDEEE
Device Start End Sectors Size Type
/dev/sda1 2048 4095 2048 1M BIOS boot
/dev/sda2 4096 2101247 2097152 1G Linux filesystem
/dev/sda3 2101248 6295551 4194304 2G Linux swap
/dev/sda4 6295552 14684159 8388608 4G Linux filesystem
/dev/sda5 14684160 41940991 27256832 13G Linux filesystem
- Device 显示了磁盘分区对应的设备文件名。
- Start 表示磁盘分区的起始位置。
- End 表示磁盘分区的结束位置。
- Sectors 表示分区占用的扇区数目。
- Size 显示分区的大小。
- type 对分区类型的名字描述,有的系统还会显示对应的 ID。
Linux 下用 83 表示主分区和逻辑分区,5 表示扩展分区,8e 表示 LVM 分区,82 表示交换分区,7 表示 NTFS 分区。有的系统还会显示 Boot 列,表示是否为引导分区。
# 利用 FDISK 划分磁盘分区
以 MBR 模式分区为例,对设备 /dev/sdb 进行分区。
fdisk /dev/sdb
输入上面的命令会进入 fdisk 命令的交互模式,按下 m 可以输出该命令的帮助信息,输入 q 放弃操作退出。
根据帮助信息的提示输入 n 来添加新的分区,此时会让我们选择创建的新的分区是主分区还是扩展分区,当我们输入 p 时创建的即为主分区,输入 e 则为扩展分区。
创建两种分区的方式大致一样,首先我们输入 p 来创建一个主分区,然后会让我们输入分区号,我们输入 1 并确认。
然后,会让我们输入分区的起始位置,并给了我们可选的范围,这里默认就好,接下来又会要求输入分区的结束位置,我们依然可以输入提示范围内的数字,但更好的方案是使用 + 带上一个数字和提示支持的单位(通常包括 {K,M,G,T,P})。
这里我们输入 +1G,现在第一个分区就划分完毕了,我么可以输入 print 来查看。
如果我们想要对分区的类型进行改变,则需要输入 t,然后输入 L 来查看 ID 和分区类型的对应关系,我们只需要输入想要改变成的分区类型对应的 ID 即可。
按照上面的方法,我们将创建的主分区改为扩展分区,然后我们再输入 n 新建一个分区,此时的提示信息与第一次有些差异,因为扩展分区只能有一个,所以刚才显示的 e 变成了 l 表示逻辑分区,接下来我们就创建两个逻辑分区。
Command (m for help): n
Partition type
p primary (0 primary, 1 extended, 3 free)
l logical (numbered from 5)
Select (default p): l
Adding logical partition 5
First sector (4096-2099199, default 4096):
Last sector, +sectors or +size{K,M,G,T,P} (4096-2099199, default 2099199): +500M
Created a new partition 5 of type 'Linux' and of size 500 MiB.
Command (m for help): n
Partition type
p primary (0 primary, 1 extended, 3 free)
l logical (numbered from 5)
Select (default p): l
Adding logical partition 6
First sector (1030144-2099199, default 1030144):
Last sector, +sectors or +size{K,M,G,T,P} (1030144-2099199, default 2099199):
Created a new partition 6 of type 'Linux' and of size 522 MiB.
现在分区的方案已经完成了(演示,并未完全分配硬盘空间),如果我们对分区的方案不满意则可以输入 d 来删除分区,删除时需要我们输入需要删除分区的区号,需要注意的是,如果我们删除的是扩展分区,那么其中的逻辑分区也会被删除。
如果满意了分区的方案,则可以输入 w 来将分区方案写入分区表中。
# PARTED
以 GPT 模式分区为例,对设备 /dev/sdb 进行分区。
如果需要进行 GPT 分区,则需要使用 parted 命令,它也可以进行 MBR 分区,但 fdisk 只能进行 MBR 分区。
使用 parted -l 命令可以查看有哪些可供使用的物理设备,直接输入 parted 默认选中的是第一个硬盘设备,你可以使用 select 加上设备名来进行切换,或者输入 quit 退出。
同 fdisk 一样,你也可以直接指定即输入 parted /dev/sdb。
接下来,需要指定分区的模式,如果是 MBR 则输入 mklabel msdos 如果是 GPT 则输入 mklabel msdos。
如果需要查看当前设备分区信息可输入 print,输入 print all 则可以查看所有设备的分区信息。
输入 mkpart 并可交互添加分区,首先会让我们输入分区的名字 test1,它就像是 Windows 中的卷标,用来描述该分区主要用来装什么内容,当然也可以不指定。
然后,会要求指定文件系统类型,默认为 ext2。确认后会让我们指定分区开始的位置,不像 fdisk 中指定的是扇区的编号,而是从多大的空间开始,由于存在 4k 对其的问题,所以一般会从 1M 开始,所以这里输入 1。
如果需要分配的大小是 200M,则在下一步提示的结束位置中输入 200 即可。
如果不使用交互模式而达到上面同样的效果,只需要输入命令 parted test1 1 200 即可,这种情况下分区的名称不能省略。
在创建分区的过程中,如果我们对某个分区的设置不满意,可以通过 rm 加上分区的编号来删除分区,而当分区完成后,由于 parted 指定的分区信息是立即生效的,所以我们直接退出即可。
注意:
- 如果我们后续指定的分区的范围包含了前面指定的,那么系统会除去之前指定的,并询问是否以余下的空间创建分区。
- 指定开始结束位置的单位默认为 MB,可以通过
unit进行改变,比如通过unit GB设置单位为 GB。
# 格式化
磁盘格式化(Format)是在物理驱动器(磁盘)的所有数据区上写零的纯物理操作过程,以建立目录区和文件分配表,同时对硬盘介质做一致性检测,并且标记出不可读和坏的扇区。
通常,格式化会导致现有的磁盘或分区中所有的文件被清除,但这并不是格式化真正的意义所在。
将设备分区之后,就需要将分区格式化为系统能够识别的文件系统。比如 Windows 上格式化的时候会问你做成 NTFS 还是 FAT32 或其他,而 Linux 上可以做成 ext2,ext3,ext4等。
无论哪一种文件系统最后都以硬盘来存储数据,我们知道硬盘的最小储存单位是 sector,但是数据所储存的最小单位是逻辑区块(Block)。因为一个 sector 只有 512 Bytes ,而磁头是一个一个 sector 的读取,也就是说,如果数据所储存的最小单位是 sector,那么读取一个 10 MBytes 的档案,则磁头必须要进行读取 (I/O) 20480 次。
逻辑区块就是为了克服这个效率上的困扰而诞生的,它是分区在进行指定文件系统的格式化时所指定的最小储存单位。如此以来同样一个 10 MBytes 的档案,磁头要读取的次数则大幅降为 2560 次。
在标准的 ext2 文件系统当中,我们将每个档案的内容分为两个部分来储存,一个是档案的属性,另一个则是档案的内容。档案的属性被存储在 inode 中,而档案的内容被储存在 Block 中。
在 inode 中的信息通常包括:
- 该档案的拥有者与群组(owner/group)。
- 该档案的存取模式。
- 该档案的类型。
- 该档案的建立日期(ctime)、最近一次的读取时间(atime)、最近修改的时间 (mtime)。
- 该档案的容量。
- 定义档案特性的旗标(flag),如 SetUID...。
- 该档案真正内容的指向 (pointer)。
因此当要读取一个树状目录下的档案时,操作系统会先读取该档案所在目录的 inode ,并取得该目录的关连区域(在 Block 区域里面),然后根据该关连资料读取该档案所在的 inode ,并再进一步经由档案的 inode 来取得档案的最后内容。
# MKFS
mkfs 命令用于在特定的分区上建立 Linux 文件系统。
mkfs [-V] [-t fstype] [fs-options] filesys [blocks]
# 常用选项
- -t: 给定档案系统的型式,Linux 的预设值为 ext2。
- -c: 在制做档案系统前,检查该 · 是否有坏轨。
- -l bad_blocks_file: 将有坏轨的 block 资料加到 bad_blocks_file 里面
- block: 给定
block的大小。 - -V: 显示详细信息。
# 实例
将上面 /dev/sdb 设备中的分区以 ext4 文件系统进行格式化。
mkfs -t ext4 /dev/sdb1
注意:
- MBR 模式下的扩展分区不能进行格式化。
Block单位的规划并不是越大越好,因为一个Block最多仅能容纳一个档案。
# 挂载
我们现在知道整个 Linux 系统使用的是目录树架构,但是我们的文件数据其实是放置在磁盘分区当中的, 现在的问题是“如何结合目录树的架构与磁盘内的数据”呢? 答案就是挂载(mount)。
所谓的“挂载”就是利用一个目录当成进入点,将磁盘分区的数据放置在该目录下;也就是说,进入该目录就可以读取该分区的意思。这个动作我们称为“挂载”,那个进入点的目录我们称为“挂载点”。
由于整个 Linux 系统最重要的是根目录,因此根目录一定需要挂载到某个分区的。至于其他的目录则可依使用者自己的需求来给予挂载到不同的分区。
更多信息可以查看 挂载。
# 查看磁盘使用情况
Linux 磁盘管理好坏直接关系到整个系统的性能问题,我们可以通过 df 和 du 来查看磁盘使用情况。
# DF
用于显示磁盘分区上的可使用的磁盘空间。默认显示单位为 KB。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
df [选项] [文件]
# 常用选项
| 名称 | 描述 |
|---|---|
| -h, --human-readable | 使用人类可读的格式。 |
| -a, --all | 包含所有的具有 0 Blocks 的文件系统。 |
| -i, --inodes | 列出 inode 资讯,不列出已使用 block。 |
| --block-size={SIZE} | 使用 {SIZE} 大小的 Blocks。 |
| -k, --kilobytes | 就像是 --block-size=1024。 |
| -m, --megabytes | 就像 --block-size=1048576。 |
| -H, --si | 很像 -h, 但是用 1000 为单位而不是用 1024。 |
| -l, --local | 限制列出的文件结构。 |
| -T, --print-type | 显示文件系统的形式。 |
| -t, --type=TYPE | 限制列出文件系统的 TYPE。 |
| -x, --exclude-type=TYPE | 限制列出文件系统不要显示 TYPE。 |
# DU
显示指定的目录或文件所占用的磁盘空间。
du [选项] [文件]
# 常用选项
| 名称 | 描述 |
|---|---|
| -a 或 -all | 显示目录中个别文件的大小。 |
| -h 或 --human-readable | 以 K,M,G 为单位,提高信息的可读性。 |
| -b 或 -bytes | 显示目录或文件大小时,以 byte 为单位。 |
| -k 或 --kilobytes | 以 1024 bytes 为单位。 |
| -m 或 --megabytes | 以 1MB 为单位。 |
| -c 或 --total | 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。 |
| -s 或 --summarize | 仅显示总计。 |
| -X<文件> 或 --exclude-from=<文件> | 在<文件>指定目录或文件。 |
| --exclude=<目录或文件> | 略过指定的目录或文件。 |
| --max-depth=<目录层数> | 超过指定层数的目录后,予以忽略。 |
| -D 或 --dereference-args | 显示指定符号连接的源文件大小。 |
| -H 或 --si | 与-h 参数相同,但是 K,M,G 是以 1000 为换算单位。 |
| -S 或 --separate-dirs | 显示个别目录的大小时,并不含其子目录的大小。 |
| -x 或 --one-file-xystem | 以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。 |
| -l 或 --count-links | 重复计算硬件连接的文件。 |
| -L<符号连接> 或 --dereference<符号连接> | 显示选项中所指定符号连接的源文件大小。 |
# 实例
以方便阅读的格式显示 test 目录所占空间情况。
du -h test
# 参考资料
- 学习 Linux,101: 硬盘布局 (opens new window)
- 玩转 Linux 之:磁盘分区、挂载知多少? (opens new window)
- 磁盘、硬盘、软盘、U 盘联系与区别 (opens new window)
- 硬盘 - 维基百科,自由的百科全书 (opens new window)
- Linux 磁盘分区和逻辑卷详解 (opens new window)
- 鸟哥的 Linux 私房菜 (opens new window)
- 计算机机械硬盘的结构和工作原理 (opens new window)
- Linux 磁盘与磁盘分区 (opens new window)
- 磁盘分区的 4K 对齐(普及帖)_知识库_IT 天空 (opens new window)
- 怎样简单的解释硬盘”4K“以及 4K 对齐? - 知乎 (opens new window)
- Linux 达人养成计划 II - 慕课网 (opens new window)
- 鸟哥的 Linux 私房菜 -- 磁盘与硬件管理 (opens new window)