图形渲染管线
渲染管线的核心功能就是利用给定的虚拟相机、三维物体、光源等信息,来生成或渲染一张二维图像。
最终图像中物体的位置和形状,由其几何结构,环境特征以及相机位置所决定。而物体的外观则会收到材质属性、光源、纹理以及着色器方程的影响。
渲染管线的架构
在一个流水线作业中可以包含若干个阶段,多个阶段可以并行执行,其中每个阶段都依赖前一个阶段的结果。在理想情况下,一个非流水线的工作可以被划分为 n 个流水线阶段,从而提升 n 倍的速度。
虽然流水线阶段可以并行执行,但是整个流水线的效率会受到其中执行速度最慢的那个阶段的影响。
在实时渲染领域中也能找到这样的流水线结构,一种粗略的划分是将渲染管线分为引用阶段 、几何处理阶段、光栅化阶段和像素处理阶段。
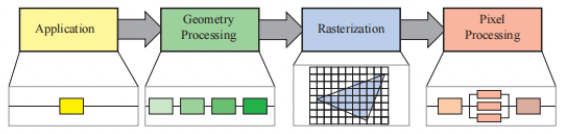
其中,每个阶段自身通常也是一个流水线。
应用阶段
应用阶段通常是在软件中实现,运行在通用 CPU 上,这些 CPU 一般都具有多核,可以并行处理多个线程的任务,这使得 CPU 可以高效执行在应用阶段负责的各种任务,包括碰撞检测、全局加速算法、动画和物理模拟等任务。
由于运行在 CPU 上,因此开发者可以完全控制在应用阶段发生的事情,开发者可以决定应用程序的具体实现方式,也可以在之后对其进行修改优化,从而提高程序的性能表现。对应用阶段的修改也会影响后续阶段的性能表现。
一些应用阶段中的任务也可以让 GPU 来进行执行,即通过使用一个叫做计算着色器(compute shader)的独立模式,该模式会将 GPU 视为一个高度并行的通用处理器。
在应用阶段的最后,需要进行渲染的几何物体会被输入到几何处理阶段中,这些几何物体被称作为渲染图元,即点、线和三角形。
几何处理阶段
运行在 GPU 上的几何处理阶段会负责大部分的逐三角形和逐顶点操作。将几何处理阶段再细分下去,可以划分为以下几个功能性阶段:顶点着色、投影、裁剪和屏幕映射。

顶点着色
顶点着色的任务主要有两个,一个是计算顶点的位置,另一个是计算那些开发人员想要作为顶点数据进行输出的任何参数,例如法线和纹理坐标等。
在早些时候,物体的光照是逐顶点计算的,通过将光源应用于每个顶点的位置和法线,从而计算并存储最终的顶点颜色;然后再通过对顶点颜色进行插值,来获取三角形内部像素的颜色,因此这个可编程的顶点处理单元被命名为顶点着色器。
随着现代 GPU 的出现,以及几乎全部的着色计算都在逐像素的阶段进行,因此顶点着色阶段变得越来越通用,甚至可能并不会在该阶段中进行任何的着色计算。顶点着色器如今是一个更加通用的单元,它负责计算并设置与每个顶点都相关的数据。
顶点位置是如何计算出来的呢?它需要一组顶点坐标来作为输入。在物体最终进入屏幕的过程中,它需要在不同的空间或者坐标系下,进行若干次变换。
最开始时,模型位于自身的模型(局部)空间中,每个模型都可以与一个模型变换相关联,以便调整自身的位置和朝向。我们可以将若干个模型变换和同一个模型相关联,这样我们就能够在不复制这个模型的前提下,在一个场景中放置同一个模型的多个副本,每个实例都拥有各自不同的位置和朝向(即模型变换)。
模型变换通常通过模型矩阵来实现。模型矩阵是一种变换矩阵,它能通过对物体进行位移、缩放、旋转来将它置于它本应该在的位置或朝向。
当对这些坐标进行模型变换之后,这个模型便位于世界坐标系或者叫做世界空间中。世界空间是唯一的,当各个模型经过各自的模型变换之后,所有的模型便都位于一个相同的空间中。此时,各个物体之间并拥有了相对的位置关系。
在定义的信息中只有能被相机(或观察者)看到的模型才会被渲染,相机在世界空间中有一个位置参数和方向参数,用于放置相机和调整相机的朝向。
为了便于后续的投影操作和裁剪操作,通常会将相机放置在原点上,并调整相机的朝向,使其看向 z 轴负半轴的方向,同时 y 轴指向上方,x 轴指向右方。为此世界空间中的所有模型,都会应用观察变换(或称视图变化)。
对观察变换的理解,可以结合相对运动进行理解,对于 A、B 两个处于同一位置的物体,如果我将 A 向前移动了十米,也可以理解为是将 B 向后移动的十米。类比此处确定的是相机位置和方位,而变换的确是模型。
在应用观察变换之后,模型的具体位置和具体方向取决于底层图形 API 的实现方式。这样形成的空间被称作相机空间(或称观察空间)。
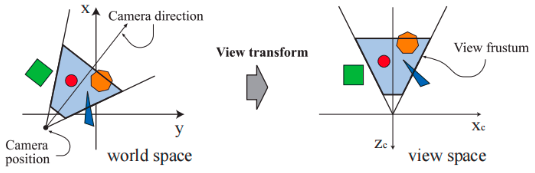
上图中假设相机进行的是透视观察,然后对观察位置和方向进行了变换。
在观察空间中需要将三维的场景变成了平面照片,同时裁剪掉摄影机屏幕外的部分,为此渲染系统还会进行投影操作和裁剪操作。这 2 个操作都会将整个可视空间变换成一个标准的立方体。
投影操作主要包括两种投影方法:
- 正交投影 - 正交视图的可视空间通常是一个长方体,正交投影会将这个可视空间变换为一个标准立方体。正交投影最主要的特征就是,投影变换之前的平行线,在正交投影之后仍然是平行的。这样的投影变换由一个位移变换和一个缩放变换组成。
- 透视投影 - 透视投影更符合人类的视角感知效果,其可视空间是一个具有矩形地面的截断金字塔,这个视椎体也会被投影生一个标准的立方体。
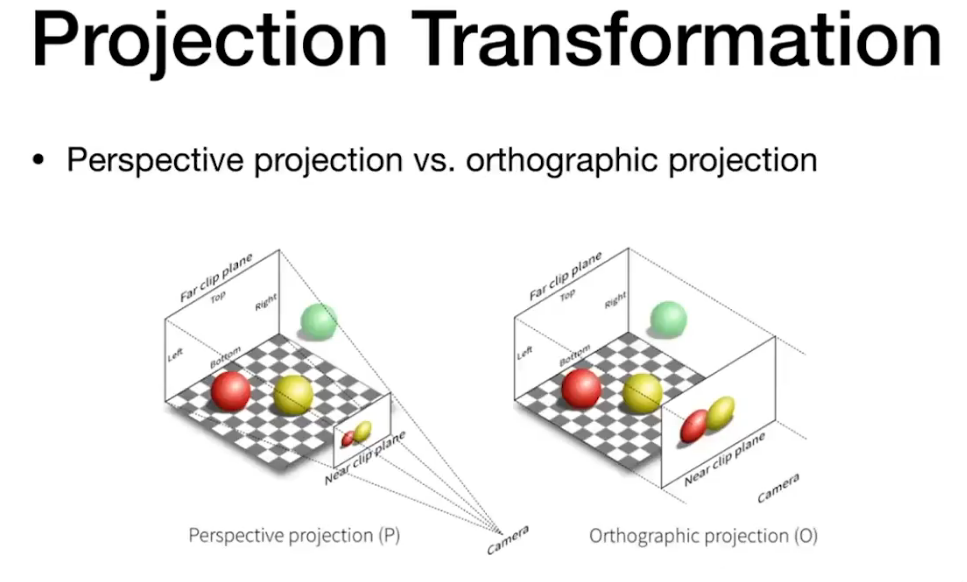
在投影变换之后,模型所处的坐标系被称为裁剪坐标系,在坐标除以 w 分量之前,事实上它们都是齐次坐标。GPU 的顶点着色器必须始终输出这种类型的坐标,以便于下一个功能性阶段(裁剪)可以正确执行。
确定光照作用于材质上所产生的效果,这个操作被称为着色,它涉及到在模型的不同位置上计算着色方程。通常来说,其中一些计算是在模型顶点的几何处理阶段中执行的,其他计算可能会在逐像素处理中完成。顶点上可以存储各种各样的数据,例如顶点位置、法线、颜色或者着色方程所需要的其他数值信息。顶点着色的结果(可能是颜色、向量、纹理坐标或者其他类型的着色数据)会被发送到光栅化阶段中进行插值,并在像素处理阶段中用于计算表面的着色。
可选的顶点处理
每个宣染管线中,都会有刚才所描述的顶点处理阶段,当完成顶点处理之后,还有几个可以在 GPU 上执行的可选操作,它们的执行顺序如下:曲面细分、几何着色和流式输出。
是否使用这些可选操作,一方面取决于硬件的功能(并不是所有 GPU 都支持这些功能),另一方面取决于程序员的意愿。
第一个可选阶段是曲面细分,想象现在有一个使用三角形进行表示的弹性小球,我们可能会遇到质量和性能的取舍问题。在 5 米外观察这个小球可能看起来会很不错,但是如果离近了看,我们会发现部分三角形,尤其是小球轮廓边缘处的三角形会非常明显。如果我们给这个小球添加更多的三角形来提高表现质量,那么当这个小球距离相机很远,仅仅占据屏幕上几个像素的时候,我们会浪费大量的计算时间和内存。这个时候,使用曲面细分可以为一个曲面生成数量合适的三角形,同时兼顾质量和效率。
下一个可选阶段是几何着色器,它也将各种类型的图元作为输入,然后生成新的顶点。几何着色器最流行的一种就是用来生成粒子。想象我们正在模拟一个烟花爆炸的过程,每颗火花都可以表示为一个点,即一个简单的顶点。几何着色器可以将每个顶点都转换成一个正方形(由两个三角形组成),这个正方形会始终面朝观察者,并且会占据若干个像素,这为我们提供了一个更加令人信服的图元来进行后续的着色。
最后一个可选阶段叫做流式输出。这个阶段可以让我们把 GPU 作为一个几何引擎,我们可以选择将这些处理好的数据输入到一个缓冲区中,而不是将其直接输入到渲染管线的后续部分并直接输出到屏幕上,这些缓冲区中的数据可以被 CPU 读回使用,也可以被 GPU 本身的后续步骤使用。这个阶段通常会用于粒子模拟,例如我们刚才所举的烟花案例。
裁剪
只有完全位于可视空间内部,或者部分位于可视空间内部的图元,才需要被发送给光栅化阶段(以及后续的像素处理阶段),然后再将其绘制到屏幕上。
完全位于可视空间内部的图元,将会按照原样传递给下一阶段;完全位于可视空间之外的图元,将不会传递给下一阶段,因为它们是不可见的,也不会被渲染;而对于那些一部分位于可视空间内部,一部分位于可视空间外部的图元,则需要进行额外的裁剪操作。
例如:一个顶点在外,一个顶点在内的线段会被可视空间裁剪,裁剪之后会生成一个新的顶点,用来替代可视空间之外的那个顶点,这个新顶点位于线段和可视空间的交点处。
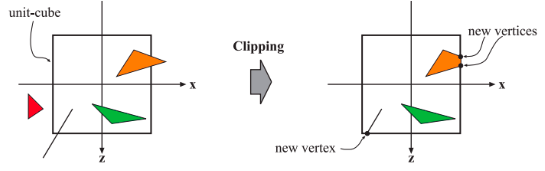
这里我们会使用投影变换生成的四维齐次坐标,来完成这个剪切操作,齐次坐标在透视空间中的三角形上进行的插值,通常并不是线性的,同时我们需要使用齐次坐标的第四个值,以便在透视投影之后进行正确的插值和裁剪。
前面,我们使用投影矩阵将可视空间变换为一个标准立方体,这意味着所有的图元都需要被这个标准立方体所裁剪。使用观察变换和投影变换保证了裁剪操作的一致性,即图元始终只需要针对这个标准立方形进行裁剪即可。
最后会进行透视除法,将得到的三角形位置转换到三维标准化设备坐标系(NDC)中。
Clip Space 是一个顶点乘以 MVP 矩阵之后所在的空间,Vertex Shader 的输出就是在 Clip Space 上(划重点),接着由 GPU 自己做透视除法将顶点转到 NDC。
透视除法只是将齐次坐标中的 W 分量转换为 1 的专用名词。
屏幕映射
位于可视空间内的图元进入到屏幕映射阶段时,其坐标还是三维的,其中 x 坐标和 y 坐标会经过视口变换被转换为屏幕坐标,屏幕坐标和 z 坐标在一起,被称作窗口坐标。
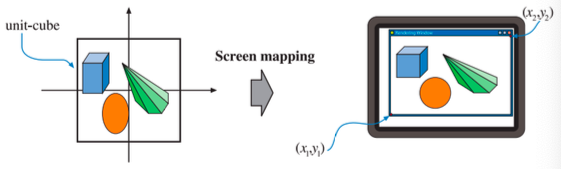
假设这个场景会被渲染到一个窗口中,窗口左下角的坐标为 (x1, y1),右上角的坐标为 (x2, y2),其中 x1 < x2, y1 < y2。屏幕映射包含了一个缩放操作,映射后的新 x, y 坐标会被称为屏幕坐标。z 坐标同样也会被映射到 [z1, z2] 的范围中,窗口坐标和这个被重映射的 z 值一起,都会被传递到光栅化阶段中。
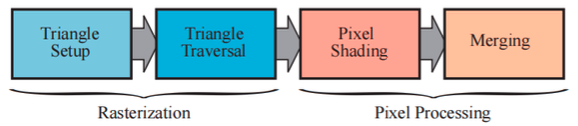
光栅化
进过前面的处理我们已经得到了三维空间中物体变换到屏幕空间中,下一个阶段的目标就是找到位于待渲染图元中的所有像素值。这个过程称作为光栅化(也被称作为扫描变换,这是一个将屏幕空间中的点转换到屏幕上像素的过程)。
光栅化阶段可以划分为三角形设置(或称图元装配)和三角形遍历两个子阶段。同时也被认为是几何处理阶段和像素处理阶段的同步点。
判断三角形和屏幕上哪些像素重合,取决于我们如何实现 GPU 管线。例如:可以使用点采样来判断是否位于三角形内部,最简单的处理可以取像素中心点来作为样本判断如果位于三角形内部则认为该像素也位于三角形内部,除此外还可以通过超采样或多重采样抗锯齿技术,来对每个像素进行采样。
三角形设置
三角形的微分、边界方程和其他数据,都会在这个阶段进行计算,这些数据可以用于三角形遍历,以及对几何处理阶段产生的各种着色数据进行插值。这个功能一般会使用固定功能的硬件实现。
三角形遍历
在这一阶段,会对每个被三角形覆盖的像素(中心点或者样本点在三角形内部的像素)进行逐个检查,并生成一个对应的片元。找到那些位于三角形内部的点或者样本,这个过程通常被称为三角形遍历,并且会对三角形三个顶点上的属性进行插值,来获得每个三角形片元的属性,这些属性包括片元的深度,以及几何阶段输出的相关着色数据等。
McCormack 等人提供了有关三角形遍历的更多信息。在光栅化阶段也会对三角形进行透视正确的插值。片元内部的像素或者样本会被输入到像素处理阶段中。
像素处理阶段
经过之前若干阶段的处理,这里我们已经找到了所有位于三角形(或者其他图元)内部的像素。像素处理阶段也可以被划分为像素着色和合并两个阶段。在像素处理阶段,会对图元内部的的像素(或者样本)进行逐像素(或者逐样本)的计算和操作。
像素着色
这里会使用插值过的着色数据作为输入,来进行逐像素的着色计算,其结果是生成一个颜色值或者多个颜色值,这些颜色值会被输入到下一阶段中。
三角形设置和三角形遍历使用了专门的硬件单元进行执行,而像素着色阶段则是由可编程的 GPU 核心来执行的。为此,程序员需要为像素着色器(在 OpenGL 中叫做片元着色器)提供一个实现程序,这个程序中包含了任何我们想要的着色计算操作。这里可以使用各种各样的技术,其中最重要的一个技术就是纹理化。
简单来说,纹理化就是将一个图像或者多个图像“粘合”在物体表面,从而实现各种各样的效果和目的。

一般这些纹理都是二维图像,但是有时候也可以是一维图像或者三维图像。简单来说,像素着色阶段最终会输出每个片元的颜色值,这些颜色值会被输入到下一个子阶段中。
合并
颜色缓冲是一个矩形阵列,它存储了每个像素中的颜色信息(即颜色的红绿蓝分量)。在之前的像素着色阶段中,我们计算了每个片元的颜色,并将其存储在颜色缓冲中,而合并阶段的任务就是将这些片元的颜色组合起来。
这个阶段也被叫做 ROP,意思是“光栅操作管线”或者“渲染输出单元”,这取决于你问的是谁。与像素着色阶段不同,执行这一阶段的 GPU 子单元,并不是完全可编程的;但它仍然是高度可配置的,可以支持实现各种效果。
合并阶段还负责解决可见性问题,即当整个场景被渲染的时候,颜色缓冲应当只包含那些相机可见的图元颜色。对于大部分或者几乎所有的图形硬件而言,这个操作是通过 z-buffer 实现的。
z-buffer(深度缓冲)具有与颜色缓冲相同的尺寸,对于其中的每个像素,它存储了目前距离最近的图元 z 值。这意味着,当一个图元要被渲染到某个像素上时,会计算这个图元的 z 值,并将其与 z-buffer 中的对应像素深度进行比较。如果这个新的 z 值比当前 z-buffer 中的像素深度更小,说明这个新图元距离相机更近,会挡住原来的图元,因此需要使用新图元的 z 值和颜色值来对 z-buffer 和颜色缓冲进行更新;如果新图元的 z 值大于对应像素在 z-buffer 中的 z 值,说明这个新图元距离相机更远,则 z-buffer 和颜色缓冲将会保持不变。
但是 z-buffer 在每个屏幕像素上,只存储了一个深度值,因此它不适用于透明物体的渲染。透明物体必须要等到所有的不透明物体都渲染完成之后,才能进行渲染,而且需要严格按照从后往前的顺序进行渲染,或者使用一个顺序无关的透明算法。透明物体的渲染是 z-buffer 算法的主要弱点之一。
模板缓冲是一个离屏缓冲区,它可以用来记录被渲染图元的位置信息,通常它的每个像素包含 8bit。图元可以通过各种各样函数来被渲染到模板缓冲中,同时模板缓冲可以用来控制渲染到颜色缓冲和 z-buffer 中的内容。
举个例子:假设现在有一个实心圆被写入到了模板缓冲中,现在我们通过一个操作,可以只允许后续图元被渲染到这个实心圆所在位置的颜色缓冲中。模板缓冲十分强大,可以用于生成一些特殊效果。所有这些在管线末尾的功能都被叫做光栅操作或者混合操作。我们也可以将当前颜色缓冲中的颜色,与三角形中正在处理的颜色相混合,从而实现一些透明效果或者颜色样本累积的效果。上文中我们提到,混合操作通常并不是完全可编程的,一般只能通过使用 APl 来进行配置。但是某些 APl 支持光栅顺序视图,也可以被称作像素着色器排序,它支持可编程的混合操作。
系统中的所有缓冲区在一起,被统称为帧缓冲。
当图元到达并通过光栅化阶段时,这些从相机角度可见的图元将会被显示在屏幕上,屏幕上所显示的内容就是颜色缓冲中的内容。由于渲染需要花费一定时间,为了避免观察者看到图元渲染并显示在屏幕上的过程,一般都会使用双缓冲机制,这意味着场景的渲染都会在屏幕外的后置缓冲区中进行。当场景被渲染到后置缓冲区之后,后置缓冲区会与显示在屏幕上的前置缓冲区交换内容。这个交换的过程通常发生在垂直回扫的过程中,因此这样做是可行的。
总结
回顾整个渲染管线,假设我们需要绘制一个三角形,那么如何确定我们要绘制的图像是一个三角形呢?
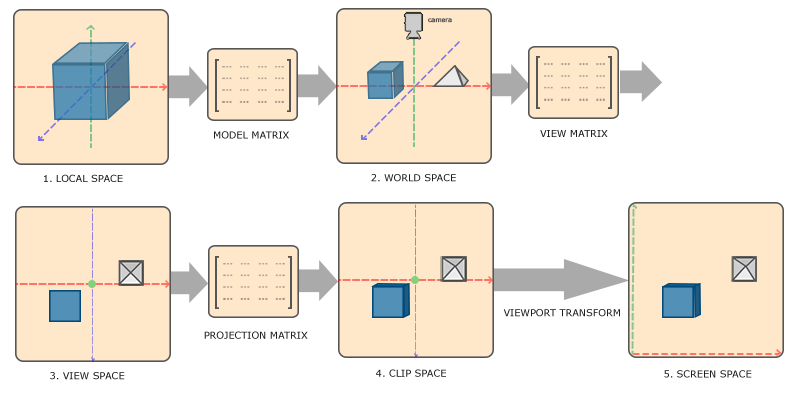
首先就需要进行模型构建,定义三角形的三个顶点来描述三角形的大小和形状。为此,我们需要建立一个局部坐标系,通过坐标位置来表示顶点信息。同时联通一些相机位置和图元信息等都发送给几何处理阶段。
在几何处理阶段中通过模型变换(物体本身的位置、朝向)和视图变换(观察的位置、视角)将物体的顶点和法线都变换到观察空间中,然后使用一个用户提供的投影矩阵,来将相机的可视空间变换到一个标准立方体,所有位于立方体外的图元都将被丢弃。
最后顶点会被通过视口变换映射到屏幕的窗口中,当这些逐三角形和逐顶点的操作完成之后,生成的结果就会被输入到光栅化阶段。
所有进入到光栅化阶段的图元都会进行光栅化,即找到所有位于图元内部的像素,然后将其发送到管线的像素处理阶段。
这一步的目标是计算出每个可见图元所覆盖像素的颜色值。与纹理(图像)相关联的三角形会使用这些纹理进行渲染。图元的可见性通过使用 z-buffer 算法来进行解决,也可以使用可选的图元丢弃操作和模板测试。每个物体都会被轮流处理,最终生成一副图像,然后显示在屏幕上。